Git 五分钟入门
作为一名技术人员,git 是我们每天都会接触到的。但你真的了解它吗?你知道 git 是如何存储我们的代码数据,又是如何保障数据安全的吗?接下来带你用五分钟的时间了解 git 的方方面面。Let's go!
一、什么是 git?
虽然 git 很多时候被用来管理代码。但如果抛开代码,git 其实是一个版本控制系统,而且是世界上最先进的版本控制系统。主要体现在三个方面:
- 数据备份:提交到 git 里面的数据会被存储起来,并推送到远程仓库进行备份;
- 历史记录:可以查看对某些数据的历史变更,以及变更的详细信息;
- 上下文对照:可以对数据的不同版本进行差异比较;
因此,git 作为版本控制系统,解决了手动管理文件变更历史的问题;
此外,git 还是一个对象数据库。数据在 git 内部就是通过一系列对象来存储的。具体内容见后文。
二、为什么要用 git
同样是版本控制系统,我们为什么不用其他工具,而使用 git 呢?主要得益于 git 有以下几个特性:
- 开源
- 源码之前,了无秘密。只要愿意,我们一窥 git 内部的优秀设计;
- 全世界优秀开发者共同维护,使得 git 更加易用、完善;
- 分布式开发
- 多人协作
- 数据冗余
- 本地+远程:大部分操作在本地完成,体验好。通常只在需要提交、拉取代码时连接远程仓库;
- 数据完整性:git 内部像区块链一样,通过 hash 计算出数据的校验和,环环相扣,不可篡改,可以保证数据安全、完整;
- 快!
- 大部分操作本地完成;
- 分支切换通过指针完成,而 SVN 是通过硬切换完成;
- 文件快照,差异对比使用快照操作
三、git 的使用
1. 相关命令
git 的操作命令从使用程度上可分为上层命令和底层命令。上层命令就是大部分人平时用到的 git add xxx、git commit -m xxx、git push 等。底层命令则是 git 真正的内部操作,需对 git 内部原理有所了解才能熟练驾驭。相关命令展示如下:
| 命令语法 | 作用 |
|---|---|
| git init | 初始化一个空仓库 |
| git add | 添加某个文件到 git 仓库 |
| git commit | 提交本次改动 |
| git push | 推送到远程仓库 |
| git reset | 将当前分支重置到某个版本 |
| git checkout | 切换分支或版本 |
| git log | 查看提交历史 |
| git hash-object | 将任意数据保存于 git 数据库中,并返回 key 值 |
| git cat-file | 查看 git 数据库中的文件内容或类型 |
| git update-index | 暂存区处理 |
| git read-tree/write-tree | 将树对象读入暂存区/将暂存区内写入一个树对象 |
| git commit-tree | 创建一个提交对象 |
| git symbolic-ref | 对 HEAD 进行操作 |
| git update-ref | 更新引用 |
| ... | ... |
2. git-flow
git 是一个分布式的版本控制系统,有非常多的特性,如分支管理、工作区、fast forward 等。但也有不少难以使用的地方:
- 如何开发一个新的 feature?对小型项目还好,稍大一点的项目同时开发的 feature 可能达到十几个,这么多 feature 如何管理?
- 线上出了 bug 如何快速修复?并且保证之后发布的所有版本都包含这个修复的 commit?
- 每次修改代码,重新发布的流程很多很繁琐,如何保证 RD 严格按照规范来操作?
此时 git-flow 出现了,我将它称为「git 工作流」,从字面意思来看,就是按照一个规定好的工作流程来操作,以保证规范性(此处解决了上述第三个问题)。git flow 严格来说是一种思想、机制,git 相关的大部分操作都可以用某些「流」来完成。它不同于许多开发人员惯用的方式。在传统开发模式下,许多人只维护了「master」和「develop」分支,相关的新功能在 develop 上开发,完成后 merge 到 master 分支上,更有甚者只有一个 master 分支。这样的工作模式对于对于并发进行多个 feature 的管理简直是个噩梦。
git flow 设定了五个分支:master、develop、hotfix、feature、release。各个分支通过不同的耦合,形成一个「流」,共同完成代码从编写到上线的一系列流程。各个分支之间的关系如下图:

(图片来自网络)
下面来逐一解释:
- master 分支:只能由 release 分支合并而来,不能在上面直接开发,以保证在任意时刻,master 分支上的代码都是稳定的;且每次合并都应该打 tag;
- hotfix 分支:当生产环境发现问题需要紧急修复时,需要且只能基于 master 分支创建一个 hotfix 分支,修复后双向 merge 到 master 和 develop,以保证生产环境和后续新功能的开发都 fix 掉此问题;
- develop 分支:此分支和 master 分支并列为常驻分支,也就是在项目中一直存在,其他分支则在相应的使命完成后会被删除;develop 基于 master 创建,有新需求时就基于 develop 分支上的某个 commit 创建不同的 feature 分支,或者在发布版本时创建出 release 分支;该分支上一般也不直接开发,而是接受其他分支的 merge;
- feature 分支:用来开发一个新功能,一旦开发完成,需要 merge 回 develop 分支。可以同时存在多个 feature 分支并行开发;
- release 分支:需要发布时,基于 develop 分支创建 release 分支,在此之上进行测试、修复 bug 等,完成后双向 merge 到 master 和 develop 分支上就可以发布了;
由此,git flow 成功将各个分支串起来,形成一个工作流,以便于快速开发迭代。
四、git 实现原理
1. 暂存区
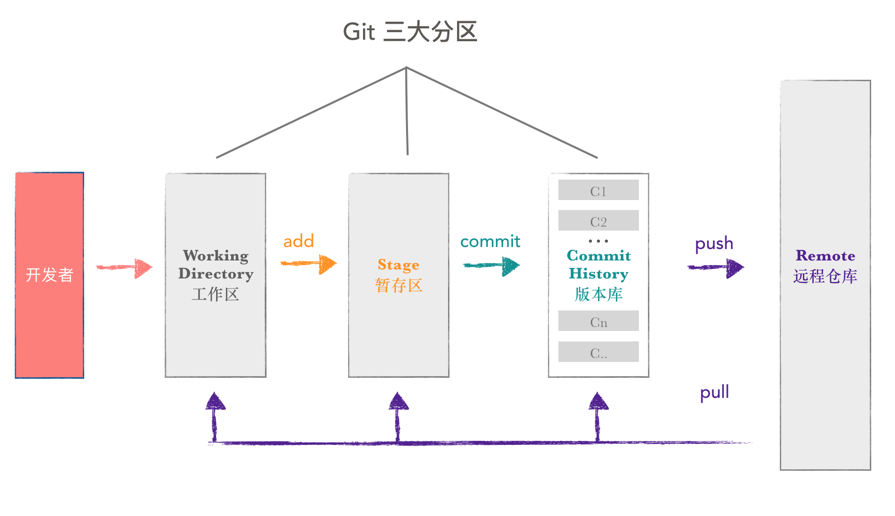
git 本地数据管理,大概可以分为三个区,工作区,暂存区和版本库。
- 工作区(Working Directory) 是我们直接编辑的地方,例如 vsocde 打开的项目,记事本打开的文本等,肉眼可见,直接操作。
- 暂存区(Stage 或 Index) 数据暂时存放的区域,可在工作区和版本库之间进行数据的友好交流。
- 版本库(commit History) 存放已经提交的数据,push 的时候,就是把这个区的数据 push 到远程仓库了。
2. 存储结构
git 相关的所有数据均存储在 .git 目录中。我们新建一个仓库,来看一下目录结构:
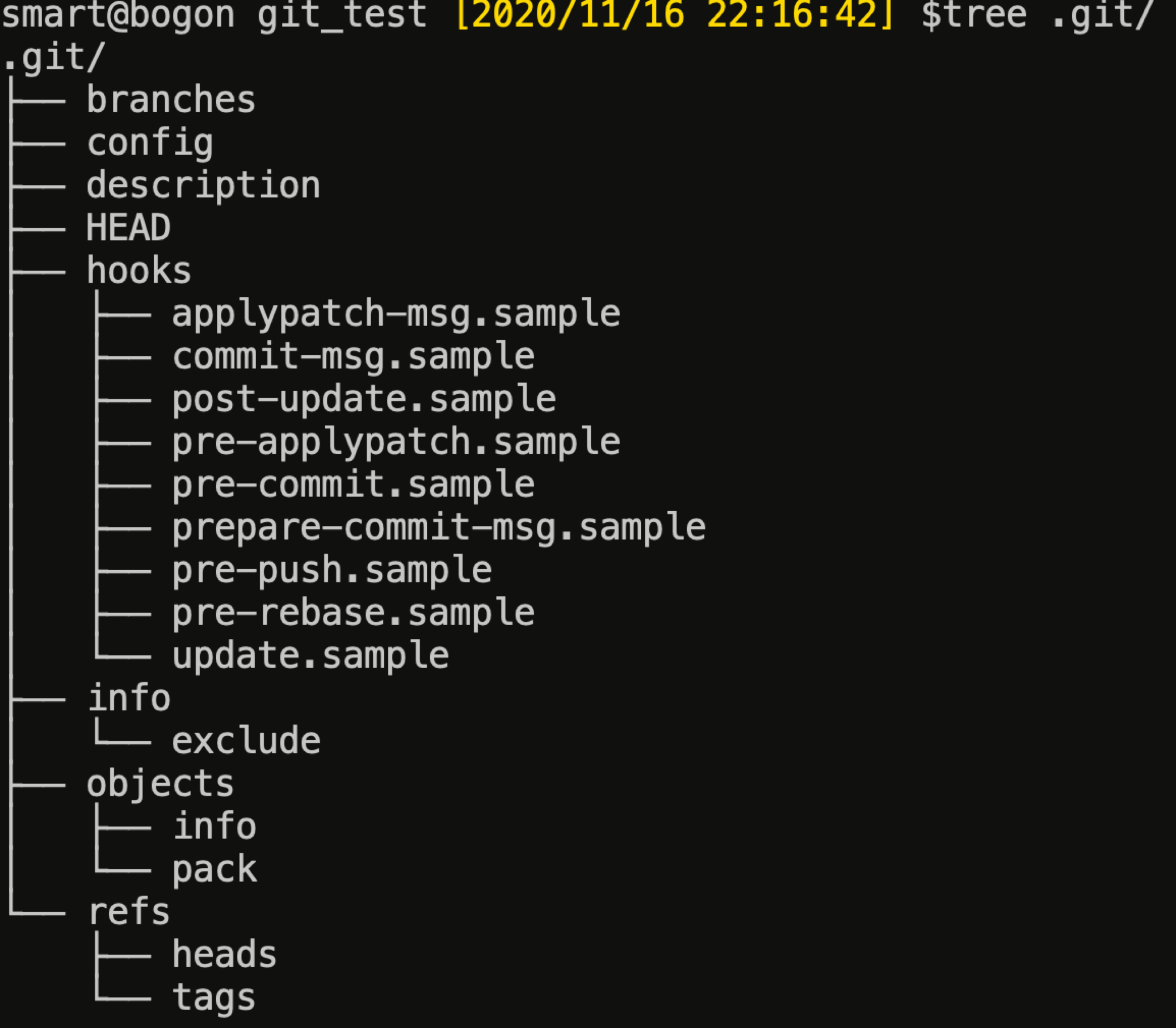
比较重要的主要是以下几个,分别在后文介绍:
- HEAD:指向目前被检出的分支;
- objects:存储所有对象数据内容(键值数据库);
- refs:存储指向数据(分支、远程仓库和标签等)的提交对象的指针;
3. 对象
git 内存存在四种对象,分别是 blob、tree、commit 和 tag 对象。每种对象都会生成一个长度为 40 的 sha1 值来标记并存储。
blob 对象
blob 对象,可以类比为 linux 系统上的 inode 节点或具体文件,是真正存储数据的对象。其布局如图所示:!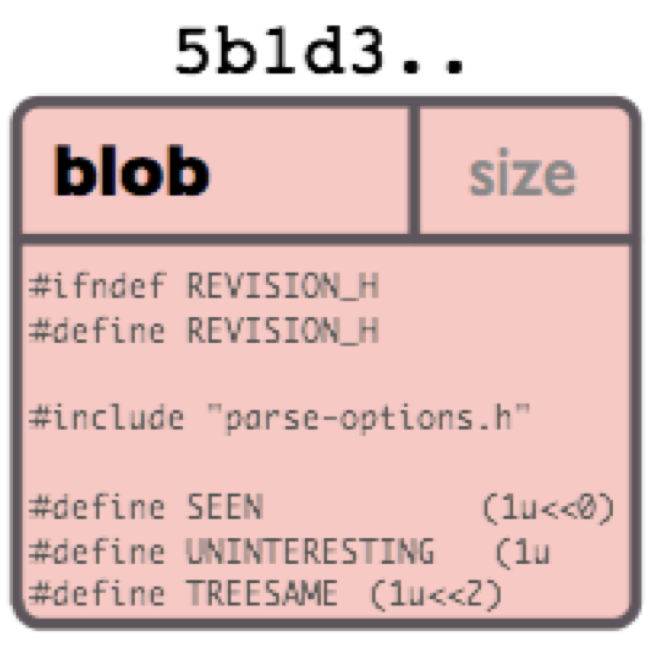
可见,一个 blob 对象由 header 和 body 组成。其中 header="blob"+数据长度,body 为实际存储的数据。然后对整个对象做 sha1 计算,得到上文所说的 sha1 值。以该值前两位作为目录名,后 38 位作为文件名,存储于 objects 目录下。文件内容为对整个对象做 zlib 压缩后的结果。如下图所示:
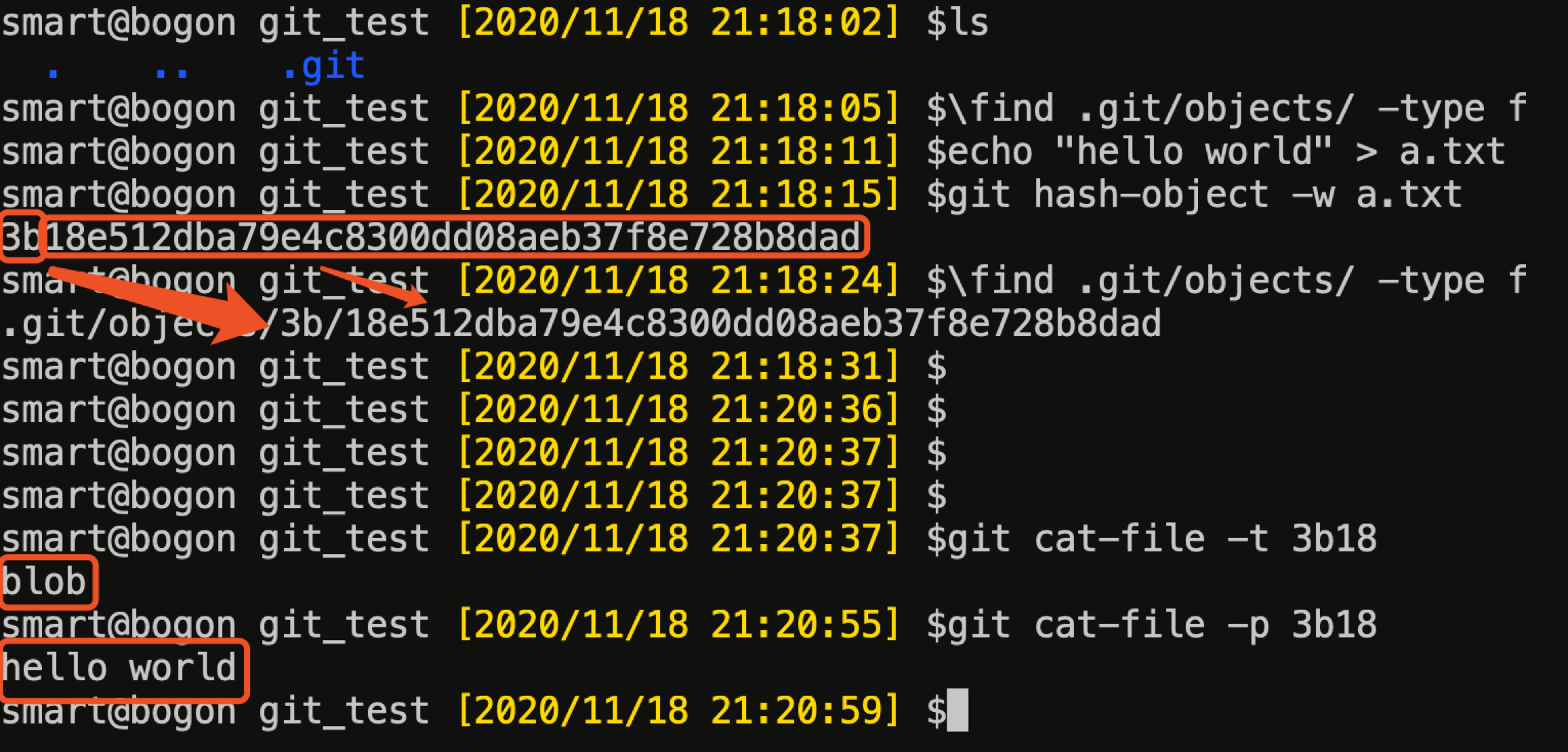
从上图可以看出,我们可以通过 git hash-object 命令,将一个文件的内容写入到一个 blob 对象中。但 blob 对象还是存在两个问题:
- sha1 哈希值难以记忆,直接给人使用较为困难;
- blob 对象中只存储文件内容,无文件名;
因此,就引出了 tree 对象。
tree 对象
如果说 blob 对象,可以类比为 linux 系统上的 inode 节点或具体文件的话,tree 对象就可以类比未 linux 系统上的目录,指向 blob 对象或者子目录对象。其结构如下图所示:

可见,tree 对象的 header 跟 blob 对象较为类似,但其 body 包含好多条记录,每条记录均指向一个子 blob 对象或子 tree 对象,并记录了子对象的文件模式(图中未画出)、类型、sha1 值和文件名。下图演示了如何生成一个 tree 对象并将上文中生成的 blob 对象添加进去:
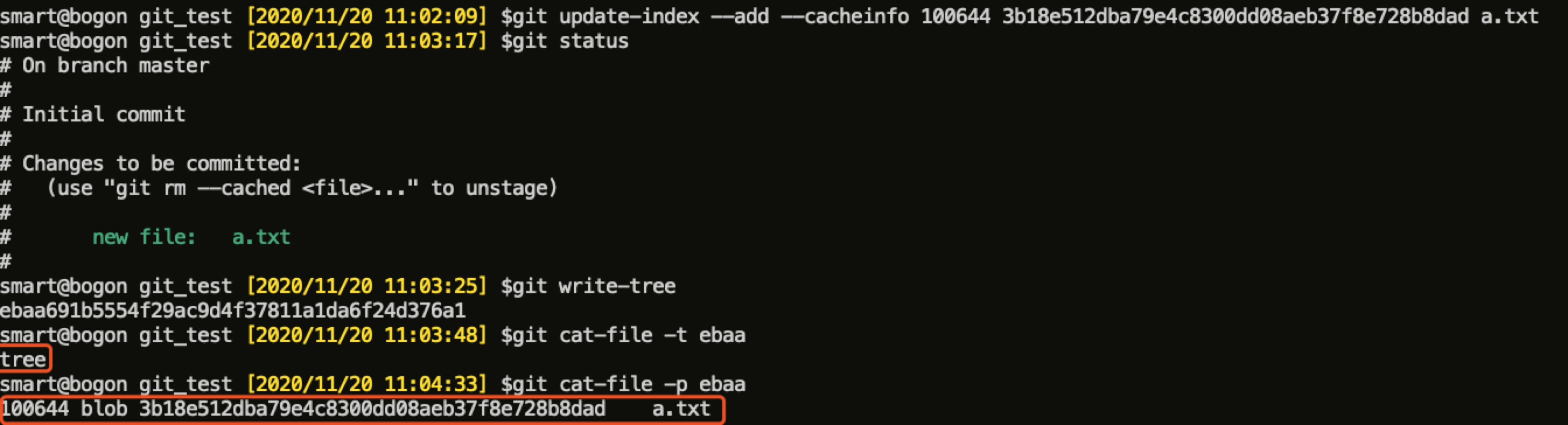
同样,tree 对象也有一些问题,最大的问题就是:该 tree 对象及其子对象是谁保存的?为什么保存?什么时间保存的?该问题可以由 commit 对象来解决。
commit 对象
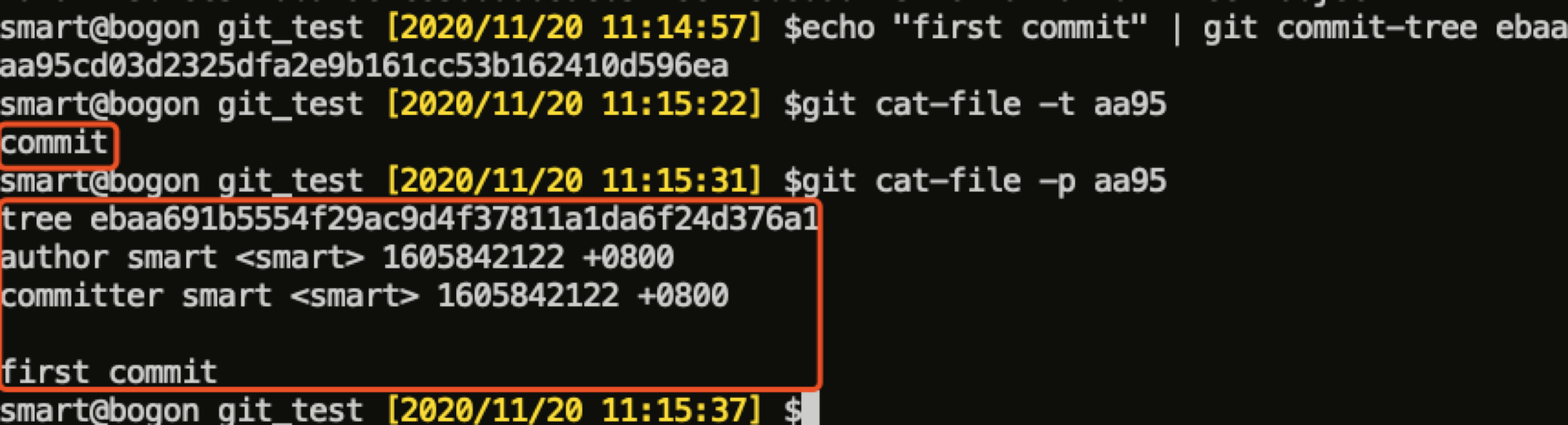
commit 对象的 body,包含其所指向的 tree 对象的 sha1 值、父 commit 对象的 sha1 值(如果有)、提交者以及相关说明信息。布局如图所示:

下图演示了如何生成一个 commit 对象:
tag 对象
tag 对象有两种:轻量 tag 对象和附注 tag 对象。
若使用 git tag xxx 命令,生成的为轻量 tag 对象。轻量标签很像一个不会改变的分支——它只是某个特定提交的引用。
而附注 tag 是存储在 git 数据库中的一个完整对象, 它们是可以被校验的,其中包含打标签者的名字、电子邮件地址、日期时间等。通过 git tag xxx -m 'yyy' 即可生成一个附注 tag 对象。其布局如下:
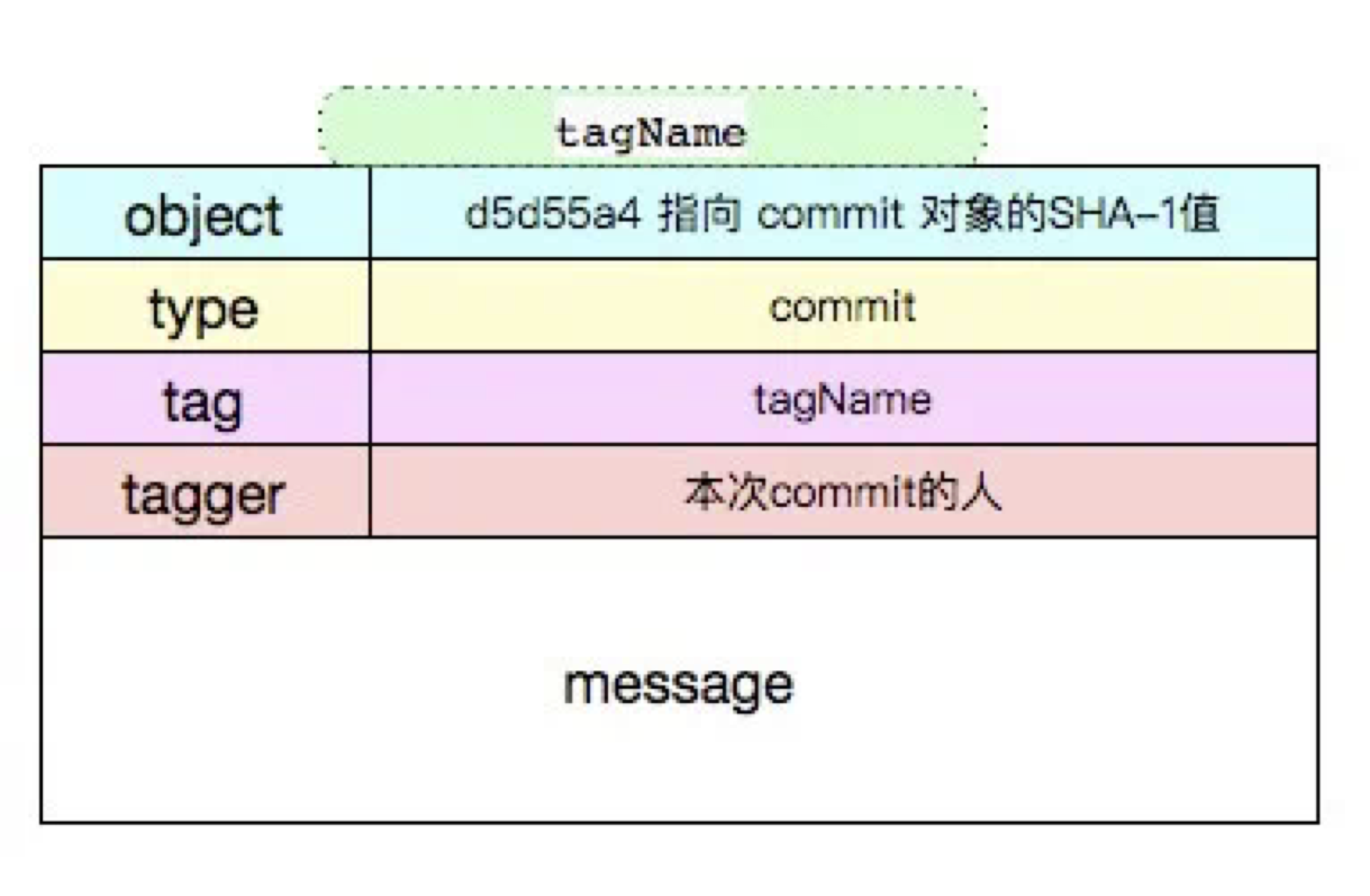
4. 引用
git 有三种引用类型:HEAD 引用、标签引用和远程引用。均存储于 .git/refs 目录下。下图演示了 HEAD 引用及标签引用:
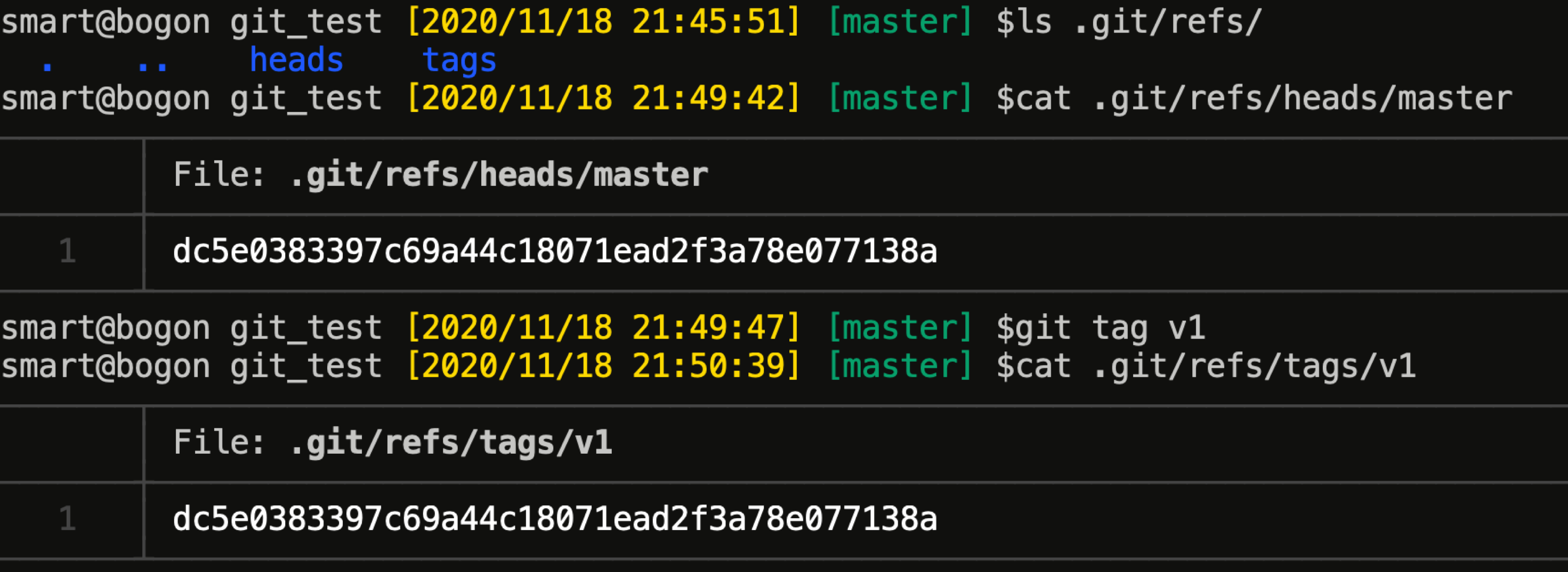
可以看出,我们平时所说的分支,其实就是一个引用,对应 .git/refs/heads 下面的一个文件,文件内容为其所指向的 commit 对象指针。另外,也印证了轻量 tag 对象其实就是一个引用。
5. HEAD 引用
.git 目录下面还有一个特殊的 HEAD 文件:

可以看出,该文件内容为 refs/heads/master,指向上文提到的分支引用的路径。因此 HEAD 文件相当于「引用的引用」,也可以理解为「指向指针的指针」,即二级指针,用于记录当前 git 工作在哪一个分支之上。
6. git 组织结构
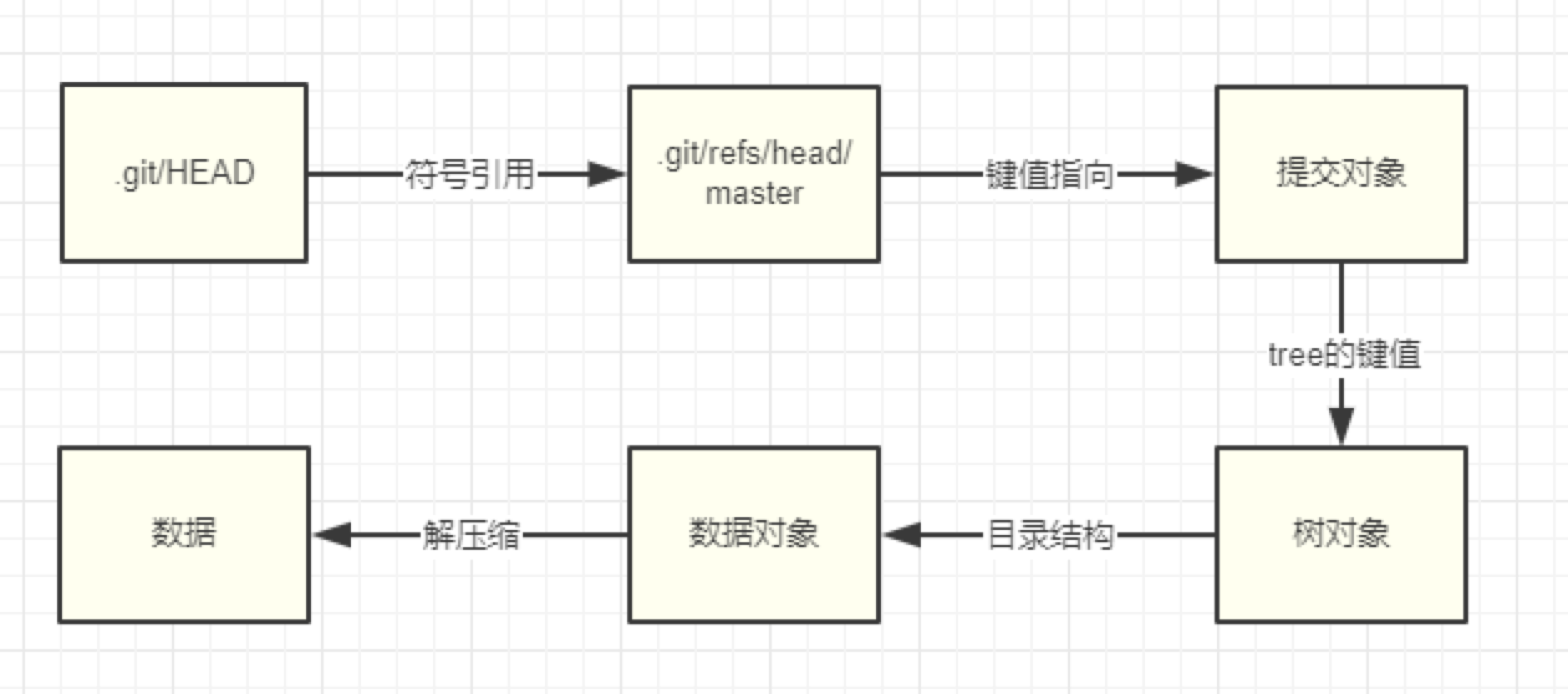
如图为 git 中各对象、引用之间的关系,可以看出,HEAD 指向引用,引用指向 commit 对象,commit 对象指向 tree 对象,其 parent 指针指向父对象。tree 对象指向 blob 对象,blob 对象中存储具体数据。